I’ve been spending a lot of time answering questions on “Stack Overflow”:http://stackoverflow.com/ lately. From what I read, most of the questions come from unexperienced developers. It’s not easy to understand their questions because they often lack code examples, stack-traces or application logs. Because of that I keep repeating a lot of stuff in the comments or in my answers. I thought that it might be better to write everything down in a blogpost, so everyone has a chance to pick it up all at once.
h2. The basics
When working with Ruby on Rails you will have to learn a lot of stuff to master debugging your own application. There are so many moving parts in a Rails app, it’s not just MVC…
* Views (Partials, Layouts, Templating-Engines)
* Controllers (Actions, Filter)
* Models (Relations, AREL, Callbacks, Database-Systems)
* Mailers
* Routes (REST, HTTP-Verbs, Constraints)
* Environments and Initializers
* Caching (Redis, Memcached)
* Assets (CSS, SASS, JavaScript, CoffeeScript, Pipelining)
* Bundler and dependency management
* Tests (RSpec, Capybara)
* gems, plugins and engines used in the app
WOW, that is a LOT and I probably forgot some stuff…
Because of this overwhelming complexity, it is very important to know the basic tools that come with Rails and that help me in my “everyday computering”:https://github.com/phoet/computering.
h3. Using rake
Rake was intended as a Make for Ruby. It’s basically a build-tool that handles tasks. It has become the swiss-army-knife of Ruby and Rails. So make sure you know when it can be useful for you! The basic commands are rake -T to get a list of _public_ commands and rake -D to get the full description of the tasks. If one of the commands fail, you can pass the --trace option to see what rake is doing under the hood and find possible error causes.
Here is a list of useful commands that I use when running into strange errors during development:
rake routes
rake middleware
rake assets:clobber
rake assets:clean
rake tmp:clear
rake log:clear
h3. Reading stack-traces
It is happening to me all the time. The application spits out an error and I have no clue what is going on. Providing meaningful error messages is one of most neglected parts in writing maintainable software. On average, Ruby is very helpful in that regard, Rails is not! Nevertheless, you should always read the errors and stack-traces because they contain helpful information like the _source file_ and the _line number_ where an error was caused. It even provides information about the context, like the calling object and the call-stack when the error happened.
Let me give you “an example exception”:http://stackoverflow.com/questions/19317128/why-i-am-getting-undefined-local-variable-or-method-role-in-cucumber-test-case/19319592:
undefined local variable or method `role' for #<:rails::world:0xc4722f8> (NameError)
./features/step_definitions/event_steps.rb:10:in `create_visitor'
./features/step_definitions/event_steps.rb:14:in `create_user'
./features/step_definitions/kid_steps.rb:107:in `/^I am exists as a parent$/'
features/manage_kids.feature:11:in `And I am exists as a parent'
What I can see at a glance:
* it’s about cucumber
* we are in a step definition
* the context object is of class Cucumber::Rails::World
* there should be a role but it is not available
* calling create_visitor caused this error
* the source of create_visitor is in event_steps.rb on line 10
The source code that matches this error is this:
# event_steps.rb
def create_visitor
@visitor ||= {
:email => "[email protected]",
:password => "test123",
:password_confirmation => "test123",
:role => Role.find_by_name(role.to_s) # this is line 10
}
end
It is just an excerpt of the code, so it’s a good idea to add real line-numbers or an anchor so other people know where we are. In this example, this would not even be necessary, because _role_ is only called once. Without knowing anything about the source, I can immediately see that the author wanted to use something that is not there.
So possible solutions to this might be to use _@role_ or maybe [email protected]_ or to have a method called _role_ or pass it in as a parameter to that method. If the test has run successfully before doing any changes, the error was probably introduced by some changes you did and should be easy to find.
_So always make sure your test suite passes before writing new code_.
h4. Side Note
Never throw away exception information unless there is a good reason! Swallowing exceptions causes a lot of pain for people that have to maintain the running application, so please at least log the error message when you rescue from something.
h3. Reading code
One of the key skills for writing code is reading code in the first place. Whether it is code I wrote some time ago, code of my coworkers or library code. It’s super important to understand the code at hand and the code that my application is executing. Compared to other languages, where one has to deal with compiled sources, it’s incredibly easy to have a look at ruby sources. I often run bundle open some_gem to look at the source or when you are not using bundler run gem env and look at GEM PATHS where your gems are installed
gem env
RubyGems Environment:
- RUBYGEMS VERSION: 2.1.5
- RUBY VERSION: 2.0.0 (2013-06-27 patchlevel 247) [x86_64-darwin12.4.0]
[...]
- GEM PATHS:
- /Users/paule/.rbenv/versions/2.0.0-p247/lib/ruby/gems/2.0.0
[...]
subl ~/.rbenv/versions/2.0.0-p247/lib/ruby/gems/2.0.0/gems/rails-4.0.0/
I also often use “dash”:http://kapeli.com/dash to get method documentation.
h2. Debugging the running server
Rails coding is often CMD+R driven. I sit in front of the browser and reload the page to see if something happens… Unluckily it does not work the way I expected, so what to do next?
h3. It’s in the logs stupid!
When I am working on a Ruby or Rails application i like to run stuff in “iTerm2”:http://www.iterm2.com with split views. One session for running spec, rails or the console and one session with the corresponding logs with tail -f log/development.log
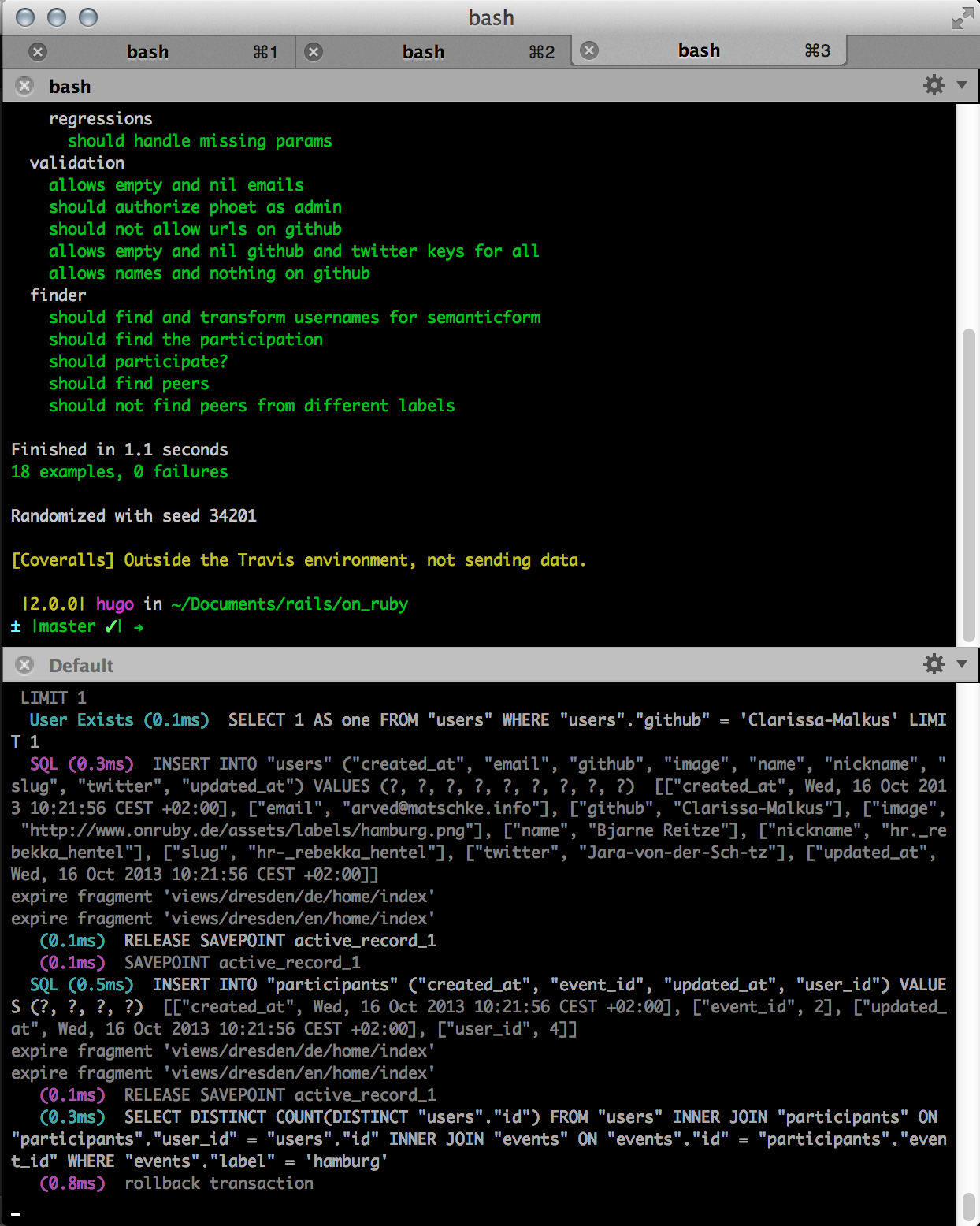
Logs help with a lot of stuff and are a powerful tool to debug your running code. Things that can be extracted from the logs:
* direct error information
** error-messages
** complete stack-traces
** logged warnings or errors (attribute accessible warnings, deprecations)
* context information
** request parameters
** request types (html, json, xhr…)
** response codes
** sql queries
** rendered views and partials
** callback informations
Since Rails introduced the asset pipeline, logs became pretty useless, because they were cluttered with asset calls. Disabling those logs does not need any ugly middleware monkey patches anymore because you can use the “quiet_assets gem”:https://github.com/evrone/quiet_assets for this purpose!
One thing that I do to pimp my logs to be even more useful is to use the “tagged logger”:http://weblog.rubyonrails.org/2012/1/20/rails-3-2-0-faster-dev-mode-routing-explain-queries-tagged-logger-store/ that was introduced in Rails 3.2. It allows you to put “even more context information into the log like the session-id and request-id”:https://github.com/phoet/on_ruby/blob/master/config/application.rb#L36:
# application.rb
config.log_tags = [
:host,
:remote_ip,
lambda { |request| "#{request.uuid}"[0..15] },
lambda { |request| "#{request.cookie_jar["_on_ruby_session"]}"[0..15] },
]
h3. Quick inspects
There are a couple of “workflows” which I tend to use in my everyday debugging, starting with simply adding p some_object, puts some_object.inspect or logger.debug some_object calls randomly to the code. For view templates i use = debug(some_object).
This helps in about 50% of the error cases because it gives me enough context to find the problem quickly.
Another thing is putting a raise some_object.to_s into the code. This is especially helpful if I want to find out when and how some part of the code is executed. Callbacks are a good example where this is a nice shorthand method for debugging.
h3. Insight tools
A running Rails server can provide a lot of useful information for debugging, especially if you curry it with the right helpers. Rails 4 already comes with some better error reporting and a route helper that can be accessed through navigating to an unknown route (“thx ecki for the clarification”:/2013/10/debugging-rails-applications-in-development/#comment-14539). I use the /routes path for this purpose:
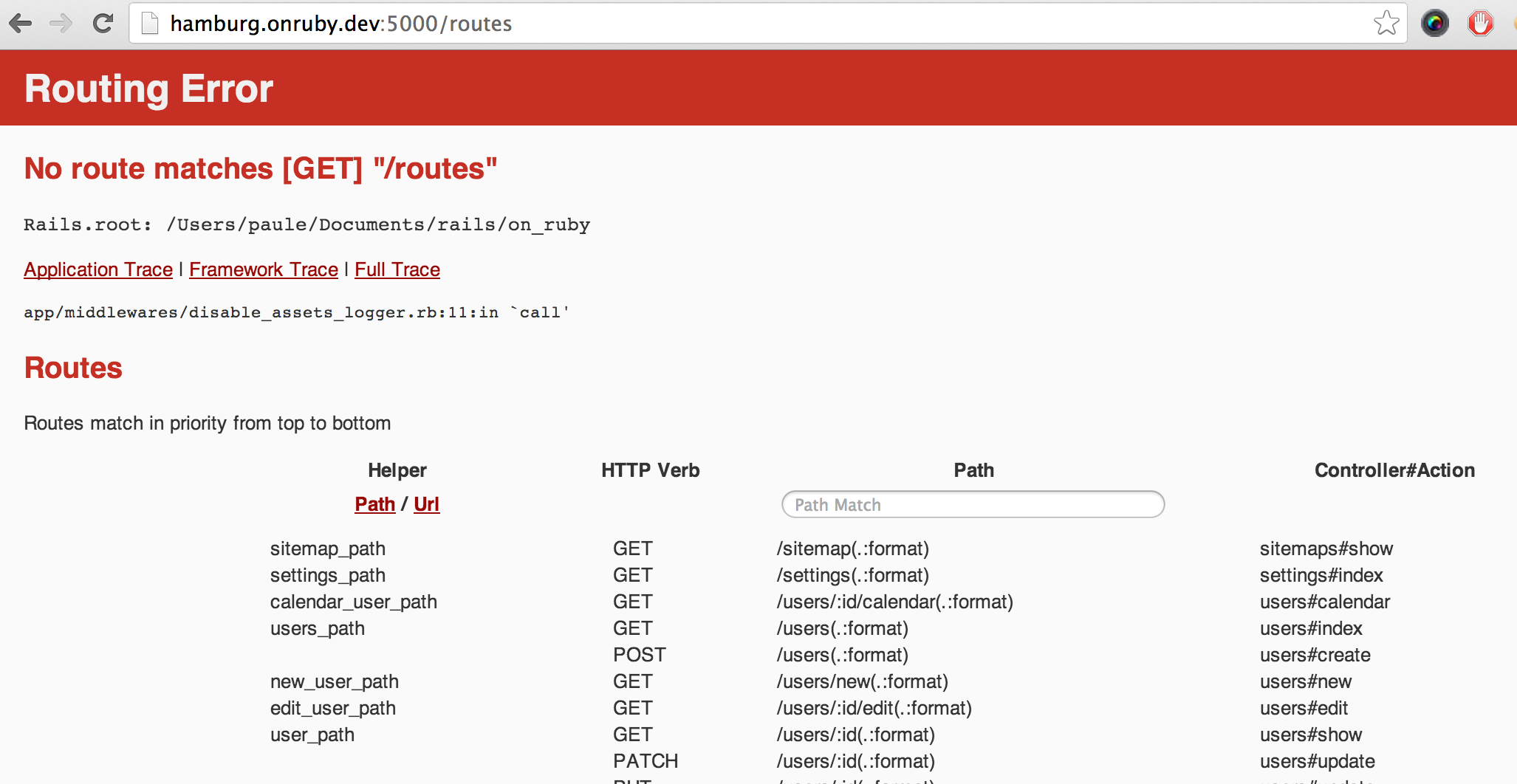
This functionality can be improved with a nice UI and a mini Rails console running in your browser if you add “Better Errors”:https://github.com/charliesome/better_errors and the “Binding of Caller”:https://github.com/banister/binding_of_caller gem. These tools allow you to dive right into the error context and find out what might have went wrong. Combining this with raising my own errors gives me a lot of flexibility to quickly get to the point where I assume that something fishy is going on in the code.
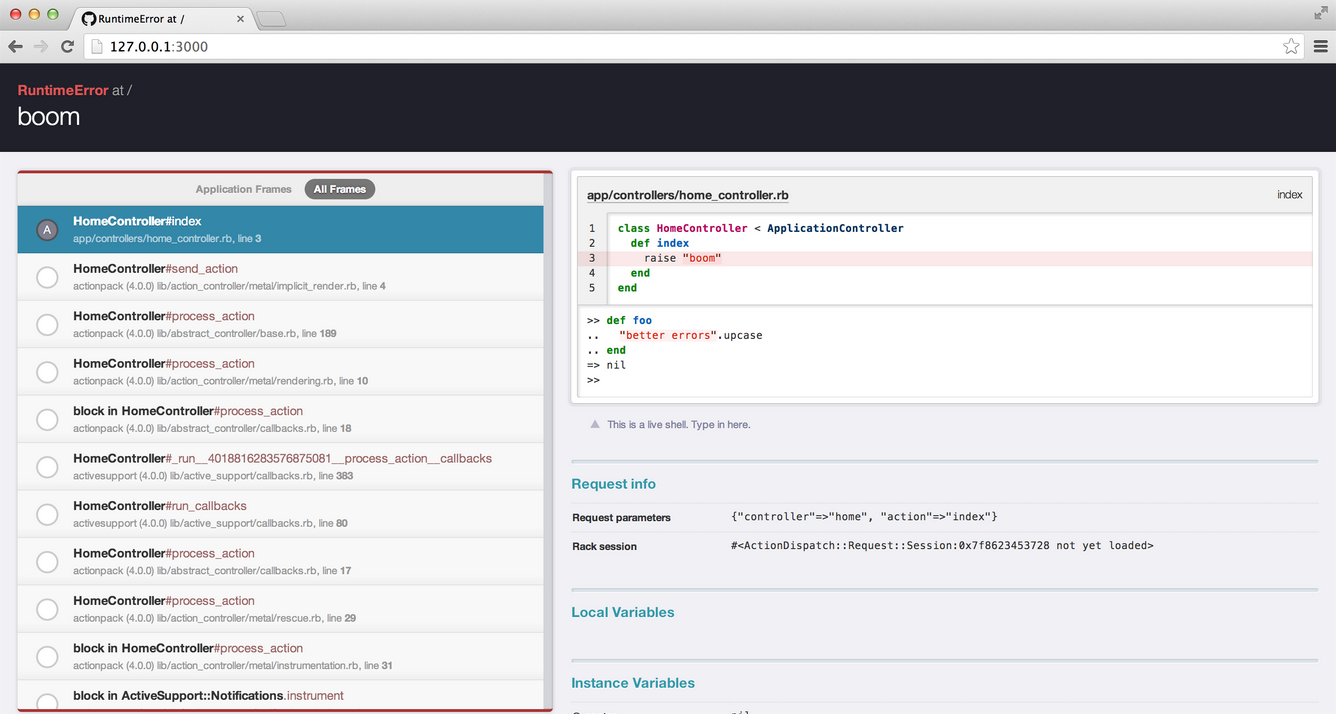
When you are doing a lot of ActionMailer related stuff, you probably want to install the “Letter Opener gem”:https://github.com/ryanb/letter_opener to develop and inspect your E-Mails.
h2. The debugger
Having tools like Better Errors is super nice, but they are only suited for usage in the Browser. This is not always possible and I fall back to real “debuggers”:http://en.wikipedia.org/wiki/Debugger that allow for moving around in the call-stack and inspecting objects at runtime.
The “ruby-debug gem”:http://bashdb.sourceforge.net/ruby-debug.html was the go-to-guy for a long time in Ruby land. It was a PITA to get this up and running in latest Ruby versions. That’s why I use the IRB replacement “pry”:https://github.com/pry/pry with a lot of extensions like “pry-debugger”:https://github.com/nixme/pry-debugger or “pry-nav”:https://github.com/nixme/pry-nav. If you want to hook into a remote Rails process (ie. running rails via foreman) you can hook into it with “pry-remote”:https://github.com/Mon-Ouie/pry-remote. Have a look at the “Pry Railscast”:http://railscasts.com/episodes/280-pry-with-rails for more information.
h2. Debugging through the console
The console is very important for me when writing new or changing existing code. I often create new finders and scopes in the console directly. A very important command in the console is reload!. It reloads all the code in the current session, similar to what happens when you hit CMD+R in the browser:
reload!; something_i_changed_in_the_editor.check_if_it_works
A thing that I find very helpful when stuck in a debugging session is the method.source_location functionality introduced in Ruby 1.9. It allows me to see where a method is defined:
user.method(:url).source_location
=> ["/Users/paule/Documents/rails/on_ruby/app/models/user.rb", 39]
h3. Use the force Luke
I like to use “pry-rails”:https://github.com/rweng/pry-rails as my default Rails Console. It enables me to browse source code, inspect objects and do a lot of other crazy stuff. Just type help in a pry session to see what commands are available. My favorite command is wtf? which shows the last raised exception and stack-trace.
h2. Debugging through testing
I love test driven development! It is an everyday part of my programming routine. The only thing that I hate when doing TDD in Rails is the slow feedback loop. I don’t like using tools like “spork”:https://github.com/sporkrb/spork-rails or “zeus”:https://github.com/burke/zeus as they introduce a lot of complexity and make debugging even harder.
So my approach to get away with minimal turnaround time is to start my new expectations by writing somthing like this:
describe User do
it "does crazy stuff" do
pry
end
end
This rspec expectation will just open a new pry session where I can start coding right away, exploring my test with direct feedback from executing the code I want to test. This eliminates all the iteration- and startup time when running red/green cycles. It is especially useful when I don’t know exactly how something should function in the first place…
h3. Debugging capybara
The last pattern is super useful when writing “acceptance tests in capybara”:https://github.com/jnicklas/capybara! I always forget how to use capybara expectations and matchers, because I write only a few of those tests. This is mainly due to “the test pyramid”:http://blog.codeclimate.com/blog/2013/10/09/rails-testing-pyramid/ and me being a backend developer.
There are also a lot more moving parts in acceptance tests, especially when running JavaScript tests in a headless browser. It’s super useful when you can just check page.body or temper with X-PATH expressions directly in the pry session.
If there is some strange behavior during test execution, I just put a breakpoint somewhere in the test and call save_and_open_page or even better: print out current_url and open the running test instance directly in the browser!
h2. Other helpful tools
The Rails ecosystem comes with a lot of tools for debugging, but it can be enhanced even further:
h3. Rails Panel
If you are using Google Chrome like me, you can use the “Rails Panel plugin”:https://github.com/dejan/rails_panel in combination with the “Meta Request gem”:https://github.com/dejan/rails_panel/tree/master/meta_request to get a Rails Developer Console in your browser. Super sweet!
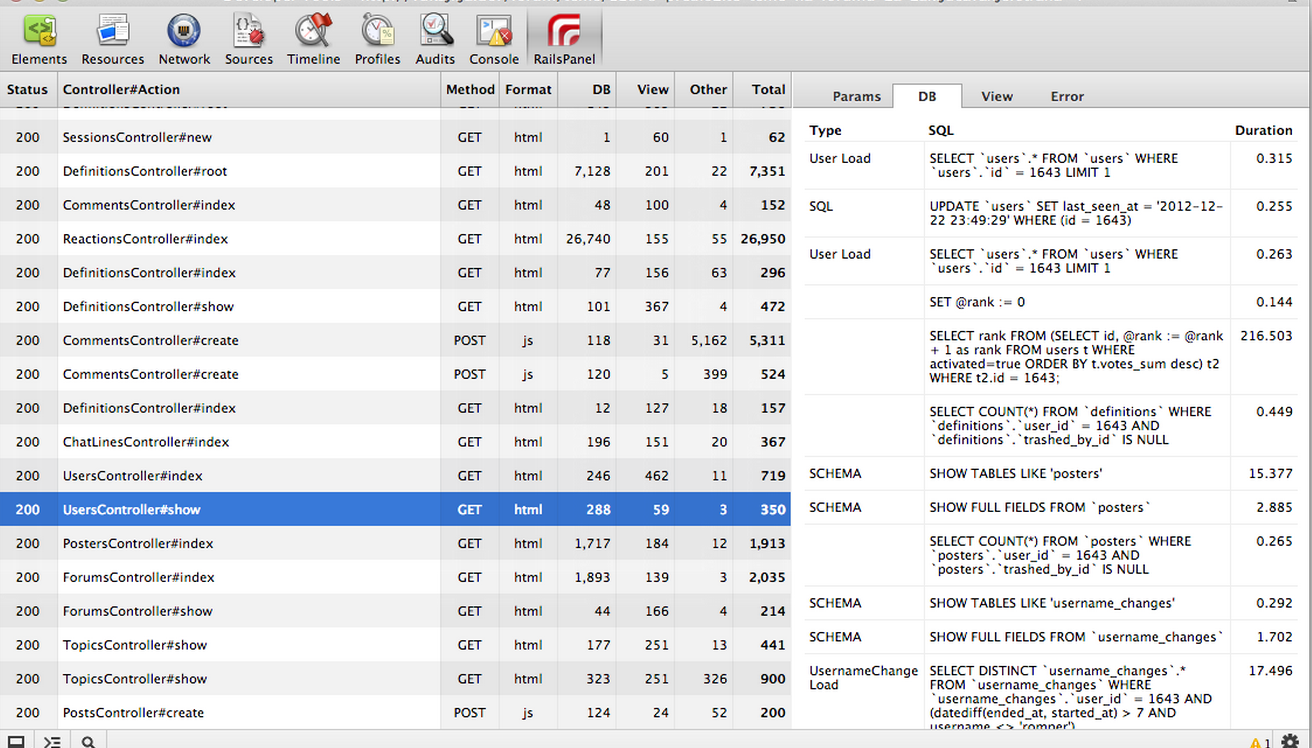
h3. cURL
If I want to look into response headers or other request/response specific information, I use curl in addition to the Chrome Developer Tools:
curl -I "http://hamburg.onruby.dev:5000/"
HTTP/1.1 200 OK
[...]
It is even possible to use the “Copy as cURL” option in the Chrome Developer Tools to get all the parameters necessary to redo some request!
h3. Navicat
I use “Navicat”:http://www.navicat.de/ as a multi db frontend. It allows me to inspect what is going on in the database, check query results, indices and create data on the fly. Always have a good client for your data stores available!
h3. GIT
“I love git”:http://git-scm.com/book! It’s not the most self explanatory tool on the planet but it helps me so much when debugging applications. Just one example here is using git bisect. It executes a command for a range of commits, so that it is possible to find out which commit introduced a problem I am trying to debug.
h2. Resources worth reading
Here are some websites that I keep referring to in a lot of my answers on stackoverflow. Go ahead and check all of them, really, I mean it!
* “Rails Guides”:http://guides.rubyonrails.org/ (“Edge Guides”:http://edgeguides.rubyonrails.org/)
* “The Ruby Pickaxe”:http://www.ruby-doc.org/docs/ProgrammingRuby/
* “RailsCasts”:http://railscasts.com/
* “API Dock”:http://apidock.com/rails
* “Ruby-Toolbox”:https://www.ruby-toolbox.com/
Hey Peter,
great Article, thanks for sharing your knowledge and your experience!
Hint: you will also get the routing info page if you request a unknown route, so I tend to access it by manual computering (ssdfdfs, e.g.).
thx for the hint ecki, i updated that part.
Weather => Whether ?
@Alper thx for pointing it out